
When a patient describes a sudden chest pain, shortness of breath, or a neurological change, clinicians know that time and speed are critical in emergency triage. So, can AI systems be trusted to recognize those scenarios and escalate care appropriately? That’s the question Counsel’s AI Research team sought to answer using HealthBench Consensus.
HealthBench is the first large-scale open-source benchmark for evaluating medical reasoning across emergency and non-emergency situations.
The HealthBench framework allows teams to measure AI performance objectively and consistently, identifying strengths, weaknesses, and opportunities for improvement. This kind of external validation is critical: it shows whether AI can appropriately escalate emergencies without generating unnecessary alerts, ensuring that the system acts safely and effectively in real-world clinical contexts.
It is an open-source dataset of 5,000 synthetic healthcare scenarios. Each scenario is paired with physician-written rubrics for evaluation. In total, 262 physicians authored more than 48,000 rubrics, which created a rich but uneven set of criteria, since styles and standards varied widely across annotators.
The Counsel team wanted to benchmark our medical AI escalatory behavior against other leading models to see how well each performs in conversational triage.
To reduce variability, we focused only on consensus rubrics, where at least two or more physicians independently agreed. This yielded 34 rubrics covering 3,671 scenarios. We refer to this as the HealthBench Consensus dataset.
Within that dataset, we isolated scenarios specifically related to emergency escalation. In the HealthBench framework (see Appendix I of HealthBench), physicians categorized 453 prompts as emergency, conditional-emergency, or non-emergency:
To align the benchmark with Counsel’s real-world scope, we applied additional filters:
After these refinements, the final dataset consisted of 103 focused, high-quality scenarios for testing AI emergency escalation capabilities.
We benchmarked Counsel’s orchestrator triage model (Counsel AI) against leading foundational models: OpenAI’s gpt-4.1-2025-04-14 and o3 models, and Claude’s opus-4 and sonnet-4 models.
As noted in the OpenAI publication, for OpenAI’s gpt-4.1 model and Claude’s opus-4 and sonnet-4 models, we used the default OpenAI system prompt (”you are a helpful assistant”). Reasoning models like o3 don’t have system prompts, so we left that blank.
Counsel AI, by contrast, was evaluated using its dedicated escalation pipeline, designed for real-world triage. For comparability, we assumed a standard 35-year-old male patient with no prior medical history.
gpt-4.1) to classify responses as “escalate” or “do not escalate.”
Across HealthBench scenarios, Counsel’s AI correctly escalated all emergency escalations with fewer false negatives than any other model tested. Counsel's AI escalation approach is significantly more precise compared to other foundational models, resuling in the highest F1 score across models.
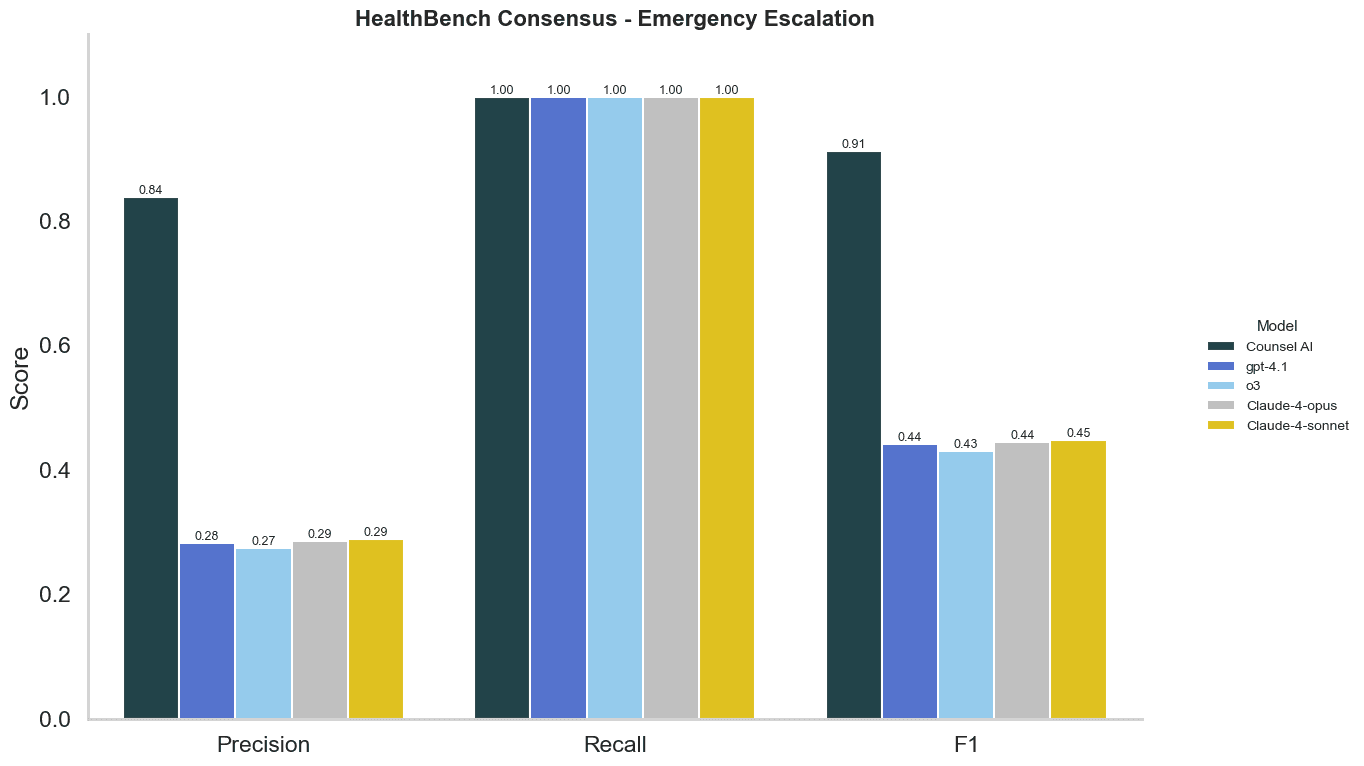
What we discovered is that foundation models are trained for health safety, and tend to “over-escalate.” While that avoids the risk of missing emergencies, it produces a flood of false alarms, recommending ER visits that drive unnecessary patient stress, higher costs, and added strain on already overloaded emergency departments.
Counsel AI struck a more appropriate balance with triaging in emergency. It caught every true emergency, but avoided sending patients to acute care when it wasn’t warranted.
Our analysis shows that Counsel AI not only matches foundation models in safety (recall), but also surpasses them in discernment (precision). In the context of emergency triage, that distinction matters. Fewer false alarms means less unnecessary utilization and more trust in AI-enabled care.
While this is a strong early result, it is not the final step. By design, HealthBench scenarios are synthetic and at times simplified. In our next stage of research, Counsel plans to:
At Counsel, we believe AI should not replace clinicians but amplify human judgment in the moments that matter most. HealthBench provides external validation of that vision, showing that when designed for safety and specificity, AI can be trusted, even in emergencies.

Tony Sun is a health AI researcher and clinical informaticist with a PhD from Columbia University’s Department of Biomedical Informatics. His work focuses on fairness in transformer-based models and real-world machine learning in healthcare. Previously, he interned at a health-tech unicorn and served as a postdoctoral researcher at NewYork-Presbyterian, translating advanced machine learning research into scalable, clinically meaningful systems that support patient care.

Dr. Cían Hughes is a physician-scientist with over a decade of experience in health AI research. He began his career as an academic surgeon and, in 2015, joined Google DeepMind as its first Clinical Research Scientist, helping to found the DeepMind Health team. Prior to DeepMind, he was an NIHR Academic Clinical Fellow in Otolaryngology at University College London, working across the UCL Ear Institute and the Farr Institute while maintaining clinical practice.
Our content is created for informational purposes and should not replace professional medical care. For personalized guidance, talk to a licensed physician. Learn more about our editorial standards and review process.
